📢이 글에서 구현할 내용
- 우리는 먼저 특정 URL을 Seed(시작 위치)로 입력받는다.
- 해당 URL의 HTML을 긁어온다.
- 긁어온 페이지에 있는 URL들을 수집한다.(URL은 중복 제거한다.)
- 깊이 우선 탐색 또는 넓이 우선 탐색 방법으로 "2."와 "3."을 반복한다.
- 시작 위치와 연관되지 않는다고 판단되면 더는 진행하지 않는다.
- 기어 다니는(크롤링) 행위를 다하고 나서 정리한 URL 테이블을 하나씩 방문해서 HTML 정보를 받아온다.
- 형태소 분석기를 사용해서 HTML에서 단어들을 추출하여 정리한다.
위 순서는 "웹 크롤러 만들기 0"에서 정리한 내용이다. 파란색으로 칠한 부분을 이번 글에서 구현해보자.
🎤형태소 분석(mecab-ya)
mecab은 리눅스, 맥 환경에서는 문제없이 설치/사용할 수 있지만, 윈도우는 기본적으로 지원되지 않기에 다른 방법을 찾아봐야 합니다.
형태소 분석(단어 추출)을 위해 mecab-ya 모듈을 설치하고 환경 구성하자. mecab-ya는 mecab이라는 오픈 소스 형태소 분석 엔진을 한국어에 맞게 수정한 mecab-ko를 쉽게 사용하게 도와주는 모듈이다. 환경 구성이 정말 편해진다.
//프로젝트 폴더로 이동 후 설치
$ npm install --save mecab-yamecab-ya를 설치한 후 생성되는 스크립트를 실행하자.
$ node_modules/mecab-ya/bin/install-mecab komecab-ya에서 제공하는 함수는 pos, nouns, morphs인데 우리는 pos만 사용할 거다. pos를 사용하게 되면 형태소를 분리해주고 각 형태소가 무엇을 의미하는지 배열을 return 해준다. 간단하게 예제를 돌려보자.
const mecab = require('mecab-ya');
mecab.pos("이건 형태소 분석을 위한 테스트용 텍스트입니다.", function (err, result) {
console.log(result);
});
분리된 형태소와 같이 생성되는 태그는 아래 페이지에서 각 의미를 파악할 수 있다.
http://kkma.snu.ac.kr/documents/?doc=postag
그리고 mecab-ya의 pos 함수를 await 가능하게 만들고, 명사인 형태소만 추출할 수 있도록 함수를 만들자.
async function asyncMecab(text) {
return new Promise((res, rej) => {
mecab.pos(text, function (err, result) {
result?.forEach(value => {
if (value[1].indexOf('NN'/*명사*/) == 0
|| value[1] == "SL" || value[1] == "OL" //외국어
|| value[1] == "SH" || value[1] == "OH" //한자
|| value[1] == "SN" || value[1] == "ON") //숫자
{
if (!mecabResult[value[0]]) mecabResult[value[0]] = 1;
else mecabResult[value[0]]++;
}
});
res();
});
});
}
☝🏼한 페이지만 단어 분석
모든 페이지를 돌아다니며 페이지를 분석하기 전에, 간단하게 예제식으로 한 페이지만 긁어와 분석해보자.
파싱에 사용할 모듈인 "node-html-parser"를 먼저 설치해주자.
$ npm install --save node-html-parsernode-html-parser 모듈에서 우리는 querySelector와 querySelectorAll 함수를 이용해서 태그 element들을 파싱 할 거다. 브라우저에서 DOM을 접근하는 것과 같이 동일한 함수들을 제공해준다.
const root = parse(response?.body);
if (!root) return;
let elements = root.querySelector('body')?.querySelectorAll('*');
if (!elements) {
elements = root.querySelector('html')?.querySelectorAll('*');
if (!elements) elements = root.querySelectorAll('*');
}이제 타깃 페이지 하나를 선정해서, 그 페이지에 있는 단어들을 추출해서 순위를 매겨보자.
필자는 NCSoft의 블로그(https://blog.ncsoft.com/) 메인 페이지를 타깃으로 분석해봤다.
const mecab = require('mecab-ya');
const request = require('request');
const { parse } = require('node-html-parser');
const seedUrl = 'https://blog.ncsoft.com/';
let mecabResult = new Map();
onePageTest();
async function onePageTest() {
await getHtmlAndMecab(seedUrl);
let sortable = [];
for (let name in mecabResult) {
sortable.push([name, mecabResult[name]]);
}
sortable.sort((a, b) => b[1] - a[1]);
console.log(sortable);
}
async function getHtmlAndMecab(url) {
const response = await getResponse(url);
if (response.request.responseContent.statusCode != 200) return null;
const root = parse(response?.body);
if (!root) return;
let elements = root.querySelector('body')?.querySelectorAll('*');
if (!elements) {
elements = root.querySelector('html')?.querySelectorAll('*');
if (!elements) elements = root.querySelectorAll('*');
}
for (let i = 0; i < elements?.length; i++) {
if (elements[i].rawTagName != "script") {
try {
await asyncMecab(elements[i].innerText);
} catch (e) { }
}
}
}
async function getResponse(url) {
const options = {
url: url,
method: 'GET',
timeout: 10000,
};
try {
return new Promise((resolve, reject) => {
request.get(options, function (err, resp) {
if (err) reject(err);
else resolve(resp);
});
});
} catch (e) { return null; }
}
async function asyncMecab(text) {
return new Promise((res, rej) => {
mecab.pos(text, function (err, result) {
result?.forEach(value => {
if (value[1].indexOf('NN'/*명사*/) == 0
|| value[1] == "SL" || value[1] == "OL" //외국어
|| value[1] == "SH" || value[1] == "OH" //한자
|| value[1] == "SN" || value[1] == "ON") //숫자
{
if (!mecabResult[value[0]]) mecabResult[value[0]] = 1;
else mecabResult[value[0]]++;
}
});
res();
});
});
}
🏃🏼♀️기어 다니며 단어 추출하기(모든 페이지)
앞서 한 페이지에 있는 단어들만 추출해보면 의미 있는 단어들이 많이 나오는 것을 볼 수 있다. 하지만 이것으로 만족할 수 없다. 크롤 하며(기어 다니며) 사이트에 있는 모든 페이지의 모든 단어들을 모아서 분석해보고, 앞에서 한 페이지만 분석한 결과와 비교해보자.
(Crawl) 먼저 이전 글에서 배웠던 Crawl 하며 URL을 수집하고,
(Scrape) 수집한 URL을 방문해서 text를 긁어오고,
(Parse) text에서 단어들을 추출해서 정리하도록 했다.
수집한 URL과 추출한 단어들을 파일로 저장하고 읽는 부분은 선택적으로 사용하면 될 거 같다.
const mecab = require('mecab-ya');
const request = require('request');
const { parse } = require('node-html-parser');
const fs = require('fs');
const path = require('path');
const DomParser = require('dom-parser');
const parser = new DomParser();
const seedUrl = 'https://blog.ncsoft.com/';
let seedOriginHost;
let resultUrlsArray = [];
let skipUrlsArray = new Set();
let mecabResult = new Map();
crawling();
async function crawling() {
//URL 수집하기
console.time('crawl time');
await crawlWebPage();
console.timeEnd('crawl time');
//수집한 URL 파일로 저장 - 선택사항
saveData(resultUrlsArray, 'urls');
//URL들 방문해서 단어 추출하기
//resultUrlsArray = readData("urls"); //저장한 URL 데이터 가져오기
console.time('mecab time');
for (let i = 0; i < resultUrlsArray.length; i++) {
await mecabUrlPage(resultUrlsArray[i]);
}
console.timeEnd('mecab time');
//추출한 단어 파일로 저장 - 선택사항
saveData(mecabResult, 'word_result');
//정렬 하기
//mecabResult = readData('word_result'); //저장한 단어 데이터 가져오기
let sortable = [];
for (let name in mecabResult) {
sortable.push([name, mecabResult[name]]);
}
sortable.sort((a, b) => b[1] - a[1]);
//출력
console.log(sortable);
}
const savePath = path.join(__dirname, "saveData");
function saveData(data, fileName) {
if (!fs.existsSync(savePath)) {
fs.mkdirSync(savePath, {recursive:true});
}
const saveFileName = path.join(savePath, fileName);
fs.writeFileSync(saveFileName, JSON.stringify(data));
}
function readData(fileName) {
const readFileName = path.join(savePath, fileName);
const readData = fs.readFileSync(readFileName);
return JSON.parse(readData.toString());
}
async function mecabUrlPage(url) {
const response = await getResponse(url);
if (response.request.responseContent.statusCode != 200) return;
const root = parse(response?.body);
if (!root) return;
let elements = root.querySelector('body')?.querySelectorAll('*');
if (!elements) {
elements = root.querySelector('html')?.querySelectorAll('*');
if (!elements) elements = root.querySelectorAll('*');
}
// console.log(elements);
for (let i = 0; i < elements?.length; i++) {
if (elements[i].rawTagName != "script") {
try {
await asyncMecab(elements[i].innerText);
} catch(e) {}
}
}
}
async function asyncMecab(text) {
return new Promise((res, rej) => {
mecab.pos(text, function (err, result) {
result?.forEach(value => {
if (value[1].indexOf('NN'/*명사*/) == 0
//|| value[1].indexOf('NP'/*대명사*/) == 0 || value[1].indexOf('NR'/*수사*/) == 0
|| value[1] == "SL" || value[1] == "OL" //외국어
|| value[1] == "SH" || value[1] == "OH" //한자
|| value[1] == "SN" || value[1] == "ON") //숫자
{
if (!mecabResult[value[0]]) mecabResult[value[0]] = 1;
else mecabResult[value[0]]++;
}
});
res();
});
});
}
async function crawlWebPage() {
try {
seedOriginHost = await getSeedOriginHost(seedUrl);
await bfs();
console.log('after bfs');
console.log(resultUrlsArray);
} catch (e) {
console.log(e);
}
}
async function getSeedOriginHost(seedUrl) {
const response = await getResponse(seedUrl);
console.log(response.request.originalHost);
return response?.request.originalHost;
}
async function getResponse(url) {
const options = {
url: url,
method: 'GET',
timeout: 10000,
};
try {
return new Promise((resolve, reject) => {
request.get(options, function (err, resp) {
if (err) {
reject(err);
} else {
resolve(resp);
}
});
});
} catch (e) {
return null;
}
}
async function bfs() {
let cur = 0;
resultUrlsArray.push(seedUrl);
while (cur < resultUrlsArray.length) {
try {
const tempUrls = await getUrlLinks(resultUrlsArray[cur++]);
await getFilteredUrls(tempUrls);
} catch (e) {}
}
}
async function getUrlLinks(url) {
try {
const response = await getResponse(url);
if (response.request.responseContent.statusCode != 200) return null;
const dom = parser.parseFromString(response.body);
const aList = dom.getElementsByTagName('a');
let urlList = aList.map(el => {
const url = el.getAttribute('href')
if(url == null || url.indexOf('#') == 0 || url == 'javascript:;') {
return null;
} else if (url?.indexOf('http') == 0){
return url;
}
const protocol = response.request.req.protocol;
const hostUrl = response.request.originalHost;
if (url.indexOf('/') == 0) {
return protocol + "//" + hostUrl + url;
} else {
return protocol + "//" + hostUrl + "/" + url;
}
});
return urlList.filter(url=>url!=undefined);
} catch (e) {
return null;
}
}
async function getFilteredUrls(urls) {
for (let i = 0; i < urls?.length; i++) {
try {
const newUrl = removeLastSlash(urls[i]);
if (skipUrlsArray.has(newUrl)) {
console.log("skip url");
continue;
}
skipUrlsArray.add(newUrl);
console.log("newUrl:", newUrl);
if (resultUrlsArray.includes(newUrl) == false) {
const response = await getResponse(urls[i]);
if (seedOriginHost == response.request.originalHost) {
console.log("url push(urls[i]) : ", urls[i]);
resultUrlsArray.push(urls[i]);
}
}
} catch (e) {
return null;
}
}
}
function removeLastSlash(url) {
if (url == '/') {
return url.slice(0, -1);
} else {
return url;
}
}
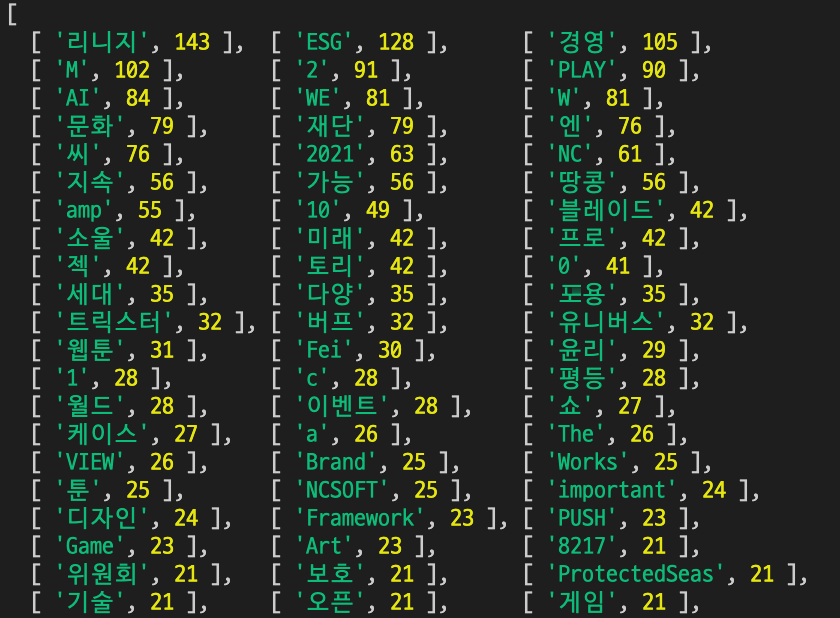
🤼♂️모든 페이지 vs 한 페이지
NCSoft 블로그의 모든 페이지를 돌아다닌 다음 얻은 단어들과 메인 페이지에서 얻은 단어들을 비교해보자.
각 단어들이 얼마만큼 언급이 되었는지 알 수 있다.

📌마치며
크롤링이 무엇인지 간단하게 크롤링을 구현하며 직접 느낄 수 있도록 글을 작성했다.
그렇기에 데이터 분석 시 의미 없는 단어들을 추출하지 않다거나, 페이지를 돌아다니는 Crawl의 방법을 효율적으로 한다거나 하는 디테일한 구현은 하지 않았다.
좀 더 크롤링에 관심이 있다면, 여기서 더 업그레이드시켜 목적에 맞는 프로젝트를 진행한다면 좋을 거 같다.
아래는 워드 클라우드를 이용해서 추출한 데이터를 시각화해봤다. 데이터가 너무 많아 약 상위 300개 정도 데이터만 추출했고, 일부 의미 없는 데이터는 수동으로 제거했다.(ex - 1, 2, 3 같은 숫자 the, a, in 등)

'개발 > Node js' 카테고리의 다른 글
| NVM status 에러 해결 방법 (6) | 2021.10.17 |
|---|---|
| [Node js]웹 크롤러 만들기3(번외)-데이터 시각화(워드 클라우드) D3 Cloud (0) | 2021.10.11 |
| [Node js]웹 크롤러 만들기1-웹 페이지 기어 다니기-BFS 넓이 우선 탐색(Crawl+Scrape) (0) | 2021.10.11 |
| [Node js]웹 크롤러 만들기0-웹 크롤러란? 우리가 만들 것은? (0) | 2021.10.11 |
| [Node js]배열,객체 데이터 파일로 쓰기/읽기-fs,path (0) | 2021.10.11 |